5. 内存优化
"GPU 的真正瓶颈不是算力,而是带宽。" —— 现代深度学习算子有 90% 的优化空间藏在内存访问里。
本章会带你从 GPU 的存储层次讲起,理解 Triton 编译器如何隐式地帮你管理共享内存 (shared memory),并用矩阵乘法的 L2 cache 优化作为完整案例,看看一行代码的改动如何带来 10%+ 的性能提升。
5.1 为什么内存优化如此重要
在深入 Triton 之前,我们先建立一个直觉:绝大多数深度学习算子是 memory-bound 的。
Microsoft Research 的论文《Data Movement is All You Need》(2020) 指出,在典型 Transformer 训练中:
- 矩阵乘法贡献了 99.8% 的浮点运算(FLOPs),但只占运行时间的 61%。
- LayerNorm、Softmax、Dropout、Mask 等"小算子"只占 0.02% 的 FLOPs,却消耗 39% 的运行时间。
为什么?因为这些小算子的计算密度(arithmetic intensity,FLOPs / byte)极低——绝大部分时间都花在 HBM ↔ SRAM 的数据搬运上。
一句话总结
- 计算密度高 → compute-bound:优化目标是让 Tensor Core 满负荷
- 计算密度低 → memory-bound:优化目标是减少 HBM 访问次数
Triton 的杀手锏正是后者——通过算子融合 (kernel fusion) + 精细的分块 (tile) 控制,把内存访问降到理论下限。
5.2 GPU 存储层次结构
要做内存优化,先要看清楚 GPU 上有哪几级"仓库",以及它们的速度差。以 NVIDIA H100 为参考:
| 层次 | 物理位置 | 容量 / SM | 带宽 | 谁来管理 |
|---|---|---|---|---|
| Registers | SM 内 | 256 KB 寄存器堆(约 64K 32-bit reg) | ≈ 算力峰值 | 编译器自动分配 |
| 共享内存 (Shared Memory) / L1 | SM 内 | H100: 228 KB;A100: 192 KB | A100: ~19 TB/s | 程序员(CUDA)/ 编译器(Triton) |
| L2 Cache | GPU 内全 SM 共享 | H100: 50 MB;A100: 40 MB | A100: ~2.2 TB/s | 硬件管理(程序员只能通过访问顺序"暗示") |
| HBM(全局内存) | 板载显存 | H100: 80 GB | H100: ~3 TB/s | 显式 load / store |
| PCIe → CPU RAM | 主机端 | 1 TB+ | ~30 GB/s | 显式 cudaMemcpy |
层级之间的速度差大约是 6~10 倍,容量则反过来大 100~10000 倍。一次 HBM 访问的延迟,足够 SRAM 跑几百个浮点运算。所以核心策略就是:让数据尽可能在快的层次里多停留、多复用。
一个常见的误解
"L2 比 HBM 快很多,所以塞进 L2 就够了" —— 错。L2 不可显式控制,且容量有限(H100 也才 50 MB);超过容量就被驱逐。最稳妥的优化是让数据进 SRAM 或 Registers。
5.3 Triton 如何管理共享内存
如果你写过 CUDA,应该对 __shared__ 关键字、__syncthreads() 和 bank conflict 印象深刻。Triton 的设计哲学截然不同:
Triton 不让你显式声明共享内存,而是由编译器自动分配。
具体做法是:编译器分析 tl.dot、tl.load、tl.store 等块级操作的操作数活跃区间(liveness analysis),把需要在多个线程之间共享的数据自动 stash 到共享内存,并在合适的位置插入同步原语。
引用 OpenAI 官方介绍:
"data can be automatically stashed to shared memory by looking at the operands of computationally intensive block-level operations (e.g.,
tl.dot) — and allocated/synchronized using standard liveness analysis techniques."
5.3.1 程序员需要操心什么
虽然不用显式声明,但你写代码时的几个选择会间接决定 SRAM 占用:
| 选择 | 影响 SRAM 的方式 |
|---|---|
BLOCK_SIZE 越大 | 单个分块占用越多 SRAM |
num_stages 越大 | 软件流水线副本数越多,SRAM 翻倍占用 |
num_warps 越多 | 单程序实例寄存器变紧,可能挤压 SRAM 预算 |
| 输入 dtype 越大(fp32 vs fp16) | 分块体积翻倍 |
经验法则(H100,228 KB 共享内存):
单核函数 SRAM 占用 ≤ 64 KB
→ 保证 4+ warps/SM 的占用率
→ 不至于因 SRAM 不够导致并行度暴跌举个例子:一个 128 × 128 的 BF16 分块 = 128 × 128 × 2 = 32 KB。一个 matmul 需要 A、B 两个分块 + 累加器,总 SRAM 大约 70~80 KB。如果再开 num_stages=3 做流水线,瞬间就到 200+ KB,已经逼近 H100 的单 SM SRAM 上限。
5.3.2 如何观察实际 SRAM 占用
Triton 编译后会把 SRAM 用量写在核函数的 metadata 里:
y = torch.empty_like(x)
kernel = softmax_kernel.warmup(
y, x, x.stride(0), y.stride(0),
n_rows, n_cols,
BLOCK_SIZE=BLOCK_SIZE,
num_stages=num_stages,
num_warps=num_warps,
grid=(1,),
)
kernel._init_handles()
size_smem = kernel.metadata.shared # 字节数
n_regs = kernel.n_regs # 每线程寄存器数
print(f"SRAM = {size_smem} bytes, regs/thread = {n_regs}")寄存器溢出 (register spill) 的隐性代价
如果 num_warps 太多或 BLOCK_SIZE 太大,寄存器不够用时 Triton 会把变量溢出(spill)到 local memory——这其实是 DRAM,比 SRAM 慢 100 倍以上。核函数不会报错,只会变慢。
可以用 ncu 检查:
ncu --metrics l1tex__data_pipe_lsu_wavefronts_mem_lg_cmd_load.sum python your_kernel.py或者直接看 Nsight Compute 的 "Memory Workload Analysis → Spill Stores"。
5.4 L2 Cache 优化:Grouped / Swizzled 程序实例排序
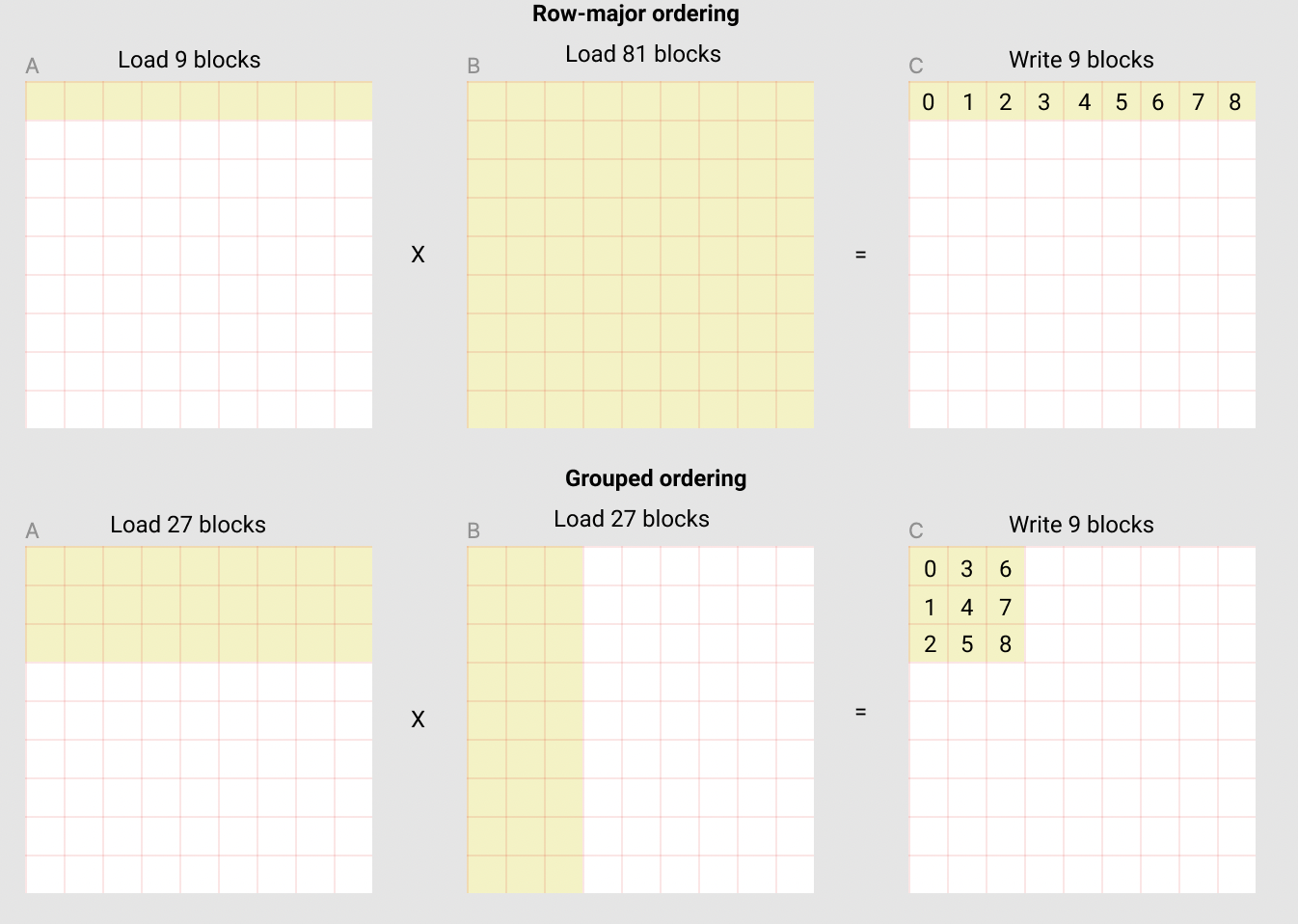
L2 是 GPU 上唯一一级跨 SM 共享的 cache。我们没法显式控制谁进 L2,但可以通过控制程序实例启动顺序来影响 L2 命中率。这一节我们用矩阵乘法来演示。
5.4.1 朴素行主序的问题
考虑 C = A @ B,假设 A、B、C 都被切成 9 × 9 个块。最直观的程序实例编号方式是行主序:
pid = tl.program_id(axis=0)
grid_n = tl.cdiv(N, BLOCK_SIZE_N)
pid_m = pid // grid_n
pid_n = pid % grid_n按这种顺序计算 C 的前 9 个输出块(即第 0 行),每个块都要读:
- A 的第 0 行的所有 9 个块 → 9 个块
- B 的第 j 列的所有 9 个块 → 9 个块 × 9 列 = 81 个块(每个 B 块只用一次)
合计 90 个块进 L2,B 几乎没复用。
5.4.2 Grouped Ordering 的思路
把程序实例按 "GROUP_SIZE_M 行一组"切分,组内按列主序遍历:
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
# 最后一个 group 可能不满
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m这样,同一组内的程序实例共享 A 的某几行,相邻组共享 B 的某几列。同样算前 9 个输出块(在 GROUP_SIZE_M=3 时分布是 3×3),只需要载入:
- A 的 3 行 × 9 块 = 27 个块
- B 的 9 行 × 3 列 = 27 个块
合计 54 个块——比朴素方案省了 40% 的 L2 流量。
下图展示了两种 ordering 的可视化对比(来源:Triton 官方文档):
5.4.3 实际性能影响
Triton 官方文档明确给出:
在 A100 上,从朴素 row-major 切换到 grouped ordering,matmul 性能从 220 TFLOPS 提升到 245 TFLOPS(+11%)。
这只是改了 5 行代码的"重排序",没有任何算法改动。这就是 L2 优化的威力。
为什么是 GROUP_SIZE_M = 8
经验值。GROUP_SIZE_M 太小(如 1,退化为行主序)→ 复用差;太大(如整个矩阵)→ 单组的 A 分块总量超过 L2 容量。8 是大多数现代 GPU 的"甜点",但严格来说也应该被纳入 autotune 搜索空间。
5.5 内存优化在矩阵乘法中的完整应用
把前面所有要点拼起来,就是 Triton 矩阵乘法核函数的核心结构。完整代码见 examples/03_matmul.py,这里只摘出关键片段:
@triton.autotune(
configs=[
triton.Config(
{'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 64,
'GROUP_SIZE_M': 8},
num_stages=3, num_warps=8),
# ... 更多 config
],
key=['M', 'N', 'K'],
)
@triton.jit
def matmul_kernel(
a_ptr, b_ptr, c_ptr,
M, N, K,
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
):
# ---- 1) Grouped 程序实例排序:优化 L2 cache 复用 ----
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((pid % num_pid_in_group) % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
# ---- 2) 构造 A、B 的初始块指针 ----
offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
# ---- 3) K 维主循环:分块累加(fp32 累加器) ----
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)
accumulator = tl.dot(a, b, accumulator)
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
# ---- 4) 转回 fp16 写回 ----
c = accumulator.to(tl.float16)
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :]
c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N)
tl.store(c_ptrs, c, mask=c_mask)把这个核函数里的内存优化要点对号入座:
- A、B 分块自动进 SRAM:编译器看到
tl.dot(a, b, ...),会把a、b这两个块自动 stash 到共享内存,不需要你写一行__shared__。 - fp32 累加器:累加器虽然是 fp32(更大),但它只在寄存器里,不进 SRAM;这样既保证精度,又不挤占共享内存。
num_stages=3~4软件流水线:让 K 维循环的下一轮tl.load与本轮tl.dot重叠执行,隐藏 DRAM 延迟。- Grouped 程序实例排序:上一节讲的 L2 复用。
- Stride 参数化:用
stride_am、stride_ak而不是硬编码行主序,支持任意 layout(行主序 / 列主序 / 转置),同时不需要额外的 transpose 核函数。 % M/% N折回:越界行/列读到的数据反正写回时被 mask 截掉,这样内层 K 循环不再需要 mask,少一组 if 判断,编译器能生成更紧凑的代码。
软件流水线的工作原理
num_stages=N 大致等价于在 K 维循环里展开 N 轮,让"加载第 i+1 轮的 A/B"与"计算第 i 轮的 dot"并行:
stage 0: load A0,B0
stage 1: load A1,B1 | compute A0·B0
stage 2: load A2,B2 | compute A1·B1 | store/accumulate stage 0
...代价是 SRAM 翻 N 倍。NVIDIA Ampere/Hopper 上常用 num_stages=2~5;AMD ROCm 文档则推荐:单 GEMM 核函数用 num_stages=0,FlashAttention 这类双 GEMM 融合用 num_stages=1。
5.6 Roofline 模型定量分析
第 4 章已经提过 arithmetic intensity;这一节把它升级成完整的 roofline 模型——一张图同时回答"该 kernel 是 compute-bound 还是 memory-bound?""距离硬件上限还有多远?""值不值得继续优化?"。
5.6.1 公式与几何意义
P_attainable (FLOP/s) = min( P_peak , BW_peak × AI )
│ │ │
│ │ └── arithmetic intensity (FLOP/byte)
│ └── HBM peak bandwidth (B/s)
└── 算力 peak (FLOP/s)几何上画 log-log 图:横轴 AI、纵轴可达 FLOP/s。
log(FLOP/s)
▲
│ ┌────────────── ← P_peak (compute ceiling)
│ ╱
│ ╱
│ ╱ ← 斜率 = BW_peak
│ ╱ (memory ceiling)
│ ╱
│ ╱
└────────────────────┴──────────────────► log(AI, FLOP/byte)
ridge point = P_peak / BW_peakridge point 左边是 memory-bound 区,右边是 compute-bound 区。算子 AI 越大,越能"爬"到算力 peak;AI 太小则永远卡在斜线上。
5.6.2 主流 NVIDIA GPU 的 ridge point
| GPU | Peak (fp16 tensor) | HBM BW | Ridge point | "右移到此 AI 才能打满算力" |
|---|---|---|---|---|
| V100 SXM2 | 125 TFLOPS | 900 GB/s | 139 FLOP/byte | 高,elementwise 全在左 |
| A100 80GB SXM | 312 TFLOPS | 2039 GB/s | 153 FLOP/byte | 同上 |
| H100 SXM (no sparsity) | 989 TFLOPS | 3350 GB/s | 295 FLOP/byte | 越新的卡 ridge 越右 |
| H200 SXM | 989 TFLOPS | 4800 GB/s | 206 FLOP/byte | HBM 升级把 ridge 拉低 |
算力 peak 是"理论峰"
A100 312 TFLOPS 是 tensor core 跑 fp16 GEMM 的理论峰值,要求 M=N=K 都很大、layout 完美、tensor core 100% 占用——实际很难超过 90%。CUDA core 上的 fp16 add/mul 算力只有 ~78 TFLOPS。比 roofline 时必须明确用哪种算力 peak。
5.6.3 几个典型算子的 AI 计算
Elementwise (add / relu)
FLOP = 1 per element
IO = 3 × dtype bytes per element (读两输入、写一输出)
AI = 1 / (3 × dtype)- fp32: AI = 1/12 ≈ 0.083 FLOP/byte
- fp16/bf16: AI = 1/6 ≈ 0.17 FLOP/byte
在 A100 上 attainable = 2039 × 0.17 = 347 GFLOP/s——离 312 TFLOPS 差 900×。所以你写得再好,elementwise 也是带宽的奴隶。
Matrix Multiplication (C = A × B, all M×N×K)
FLOP = 2 × M × N × K
IO = (M×K + K×N + M×N) × dtype (读 A 读 B 写 C)
AI = 2MNK / ((MK + KN + MN) × dtype)当 M = N = K = D(方阵简化):
AI = 2 D³ / (3 D² × dtype) = (2 D) / (3 × dtype)- fp16, D=64: AI = 128/6 ≈ 21 FLOP/byte → memory-bound (远小于 153)
- fp16, D=512: AI = 1024/6 ≈ 170 FLOP/byte → 刚跨过 ridge,compute-bound
- fp16, D=4096: AI = 8192/6 ≈ 1365 FLOP/byte → 深度 compute-bound
结论:GEMM 的 AI 与矩阵边长成正比,所以大矩阵才打得满 tensor core。小 GEMM(D < 256)一定是带宽瓶颈,这也是为什么 grouped GEMM、batched GEMM 要把多个小矩阵拼成大矩阵。
LayerNorm / Softmax (按行)
读一遍写一遍 → IO = 2 × N × dtype;FLOP ≈ 5N(mean + var + scale + add):
AI ≈ 5 / (2 × dtype) = 5/4 = 1.25 (fp16)依然远低于 ridge → 永远 memory-bound → 优化方向只有"减少 HBM 往返" → 这正是 fused LayerNorm / online softmax 的存在意义(详见第 7 章)。
FlashAttention (block tile 内)
经过 tiling 后单 program 内:
AI_attn ≈ d_head / (4 × dtype_bytes) (近似)- fp16, d_head=64: AI ≈ 8 → memory-bound
- fp16, d_head=128: AI ≈ 16 → memory-bound
- 整体 attention:所以 FlashAttention 仍然是带宽优化为主
5.6.4 用 roofline 决策"还要不要继续优化"
实测得到 achieved_FLOPS,与 roofline 比对:
roofline_limit = min(P_peak, BW_peak × AI)
efficiency = achieved_FLOPS / roofline_limitefficiency > 90%:到顶了,停手。剩下的优化空间小于 10%。60% < efficiency < 90%:值得调,重点放在指令级(向量化、register spill)。efficiency < 50%:八成有 coalescing / 同步 / spill 问题,先用 Nsight Compute 跑 roofline section 找瓶颈。
Nsight Compute 直接出 roofline
ncu --set roofline -k my_kernel python run.py会自动生成 hierarchical roofline(同时画 HBM、L2、L1 三条斜线),可视化非常直观。
5.7 Bank Conflict 详解
Triton 编译器会自动规避 bank conflict,但理解它是 debug 性能异常时的必备肌肉。
5.7.1 硬件:32 banks × 4 bytes
shared memory 物理上分 32 个 bank,每个 bank 一次能服务 1 个 32-bit word / 周期。地址到 bank 的映射:
bank_id = (address / 4) % 32形象地画:
addr: 0x00 0x04 0x08 0x0C ... 0x7C 0x80 0x84 ...
bank: 0 1 2 3 ... 31 0 1 ...也就是 每 128 B (= 32 × 4) 重复一轮。同一时刻,一个 warp 的 32 个 lane 要访问 shared memory:
- 所有 lane 访问不同 bank → 一周期完成,速度 = 寄存器级
- k 个 lane 访问同一 bank 的不同地址 → 串行 k 次,慢 k×(k-way bank conflict)
- 多个 lane 访问同一 bank 的同一地址 → 广播,1 周期(无冲突)
5.7.2 经典冲突场景
场景 1:列读取一个行主序矩阵
__shared__ float sm[32][32];
// 每个 lane 读不同列:threadIdx.x 是 lane id
float v = sm[threadIdx.x][0]; // 全部访问 bank 0 → 32-way conflict地址:&sm[0][0] + threadIdx.x × 32 × 4 = 全部对应 bank = (offset/4) % 32 = (threadIdx.x × 32) % 32 = 0。32-way 冲突,速度只剩 1/32。
场景 2:stride 为 2 的幂
float v = sm[threadIdx.x × 2]; // stride=2,2-way conflict
float v = sm[threadIdx.x × 4]; // stride=4,4-way conflict只要 stride 是 2 的幂(且小于 32),就会冲突。stride = 33(任何奇数)则完全无冲突——这就是 CUDA 常用的"padding 一列防 bank conflict"技巧。
5.7.3 Triton 编译器的 swizzle 策略
Triton 在 TTGIR 阶段对 #shared layout 的 tensor 自动加 XOR-based swizzling:把 row i 的存放位置从"naive 行主序"改成"按某种 XOR pattern 偏移",让任何按行或按列的 warp 读取都不撞 bank。
CUTLASS 风格的 swizzle 公式(Triton 也大致用这个):
swizzled_offset = (row XOR (col >> log2(M))) * stride + col参数 M 控制 swizzle 周期(典型 8 或 16)。效果是把 shared memory 的"逻辑列"重排成 bank-conflict-free 的物理布局。
代码层面,Triton 用户完全不需要写任何 swizzle 注解——只要操作走 tl.dot(或被识别为"用作矩阵乘的操作数"),编译器就会自动加 swizzle layout。这也是为什么 Triton 的 GEMM 能达到 cuBLAS 的 90%+ 而你只写了 30 行 Python。
什么时候 Triton 不能自动 swizzle
- 用
tl.atomic_add/tl.atomic_max直接写 shared memory 类似模式 - 自定义 reduce 中手动按非常规模式 gather
- 这些情况会留下原始访问模式,可能产生 conflict
用 Nsight Compute 验证:看 Memory Workload Analysis → Shared Memory 那一栏的 "Bank Conflicts" 数。0 = 完美,几 K = 严重。
5.7.4 用 Nsight Compute 抓 bank conflict
ncu --metrics \
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_ld.sum,\
l1tex__data_bank_conflicts_pipe_lsu_mem_shared_op_st.sum \
-k my_kernel python run.py前者是读冲突数、后者是写冲突数。理想值都是 0。
5.8 Software Pipelining 与 num_stages 深入
前面提过 num_stages 控制多缓冲深度。这一节把"多缓冲"具体到 Triton 编译器做了什么、SRAM 怎么吃、应该选几。
5.8.1 为什么需要软件流水线
不开流水线(num_stages=1)的 K 维循环:
for k:
load A[k], B[k] ← 等 HBM ~400 cycle
dot(A[k], B[k], C) ← tensor core ~64 cycle
(空等)
────────────────
single iter ~ 464 cycle每轮 86% 的时间在干等内存。
开 num_stages=3,编译器把循环展开成:
prologue: load A[0],B[0]; load A[1],B[1]; load A[2],B[2]
main loop:
for k = 2..K-1:
wait_load(k-2) ← cp.async 等前 2 轮的数据到达
dot(A[k-2], B[k-2], C)
issue_load(A[k+1], B[k+1]) ← 同时发起下下下轮
epilogue: 处理最后两轮执行时序:
time →
load A0 load A1 load A2 load A3 load A4 ...
dot A0 dot A1 dot A2 ...
↑
load 与 dot 完全重叠理论加速:当 t_load ≈ t_compute 时,吞吐翻 1.5~2×。
5.8.2 num_stages = 1/2/3/4/5 的行为对比
| num_stages | SRAM 占用 | 隐藏 HBM 延迟 | 适用场景 |
|---|---|---|---|
| 1 (no pipeline) | 1× | 完全不隐藏 | 调试、超小矩阵、AMD ROCm 单 GEMM |
| 2 | 2× | 隐藏 ~50% | 安全默认值、SRAM 紧张时 |
| 3 | 3× | 隐藏 ~75% | A100 fp16 GEMM 甜点(128×256×64 块) |
| 4 | 4× | 隐藏 ~85% | H100 大 tile GEMM、HBM3 带宽更高时 |
| 5+ | 5×+ | 边际收益小 | 一般不用,除非 K 维特别大 |
计算 SRAM:以 fp16 GEMM 为例
单 stage SRAM = (BLOCK_M × BLOCK_K + BLOCK_K × BLOCK_N) × 2 bytes(128, 256, 64) fp16, num_stages=3:- 单 stage =
(128×64 + 64×256) × 2 = (8192 + 16384) × 2 = 49152 B = 48 KB - 3 stage =
144 KB - A100 上限 163 KB → 可以装
- H100 上限 228 KB → 还能再开
num_stages=4
- 单 stage =
(256, 256, 64) fp16, num_stages=3:- 单 stage =
(256×64 + 64×256) × 2 = 65536 B = 64 KB - 3 stage =
192 KB - A100 上限 163 KB → 装不下,编译器会自动降到
num_stages=2(128 KB),失去一档流水
- 单 stage =
5.8.3 Triton 编译器的 pipeline pass 做了什么
TTGIR 阶段有个 tritongpu-pipeline pass,做四件事:
- 识别可流水的循环:循环必须有"加载 + 计算 + 累加"的标准结构。
- 插入
cp.async:把同步的ld.global → shared改成异步的cp.async.cg,让 load 不阻塞后续指令。Ampere/Hopper 上的cp.async是硬件特性。 - 多缓冲分配:在 shared memory 里给每个 stage 分配独立 buffer,避免数据覆盖。
- 插入 barrier:
cp.async.wait_group等待第i - (num_stages-1)轮的 load 完成,再去 dot。
这就是为什么 cp.async 一旦失败(比如 transfer size < 4 bytes),整个 num_stages>1 就 fall back(参见 triton#5882)。
5.8.4 最佳 num_stages 选择策略
# 经验起点表
if op_type == "single GEMM":
if device == "A100":
candidates = [3, 4] # fp16 GEMM 甜点
elif device == "H100":
candidates = [3, 4, 5]
elif device == "AMD MI300":
candidates = [0, 1] # ROCm 推荐 num_stages=0 单 GEMM
elif op_type == "fused two GEMMs (FlashAttention)":
candidates = [1, 2] # SRAM 紧,stages 不能多
elif op_type == "elementwise / reduction":
candidates = [1] # 没有 HBM-compute 重叠机会放进 autotune 自动搜:
@triton.autotune(
configs=[
triton.Config({'BLOCK_M':128,'BLOCK_N':256,'BLOCK_K':64,'GROUP_SIZE_M':8},
num_warps=8, num_stages=3),
triton.Config({'BLOCK_M':128,'BLOCK_N':256,'BLOCK_K':64,'GROUP_SIZE_M':8},
num_warps=8, num_stages=4),
# ...
],
key=['M', 'N', 'K'],
)OOM-on-shared 警告
num_stages 配高了,编译器会报 triton.runtime.errors.OutOfResources: out of resource: shared memory, Required: 262176, Hardware limit: 232448。看到立刻减小 BLOCK_M/N/K 或 num_stages。OpenAI 在 GTC 2025 Blackwell 演讲里展示过这条原话错误信息——是 Triton 用户的"老朋友"了。
5.9 寄存器压力与 Spill 分析
寄存器溢出 (register spill) 是 Triton 最常见的"沉默性能杀手"——核函数不报错,只是悄悄慢 2~10 倍。
5.9.1 GPU 寄存器硬件参数
| 项目 | V100 | A100 | H100 |
|---|---|---|---|
| 单 SM 32-bit 寄存器数 | 65536 | 65536 | 65536 |
| 单 SM 寄存器文件总容量 | 256 KB | 256 KB | 256 KB |
| 单 thread 寄存器上限 | 255 | 255 | 255 |
| 单 thread block 寄存器上限 | 65536 | 65536 | 65536 |
| 单 SM 最大并发 thread | 2048 | 2048 | 2048 |
从这些数算几个关键阈值:
要达到 100% occupancy(2048 thread/SM):
regs/thread ≤ 65536 / 2048 = 32
要达到 50% occupancy(1024 thread/SM):
regs/thread ≤ 65536 / 1024 = 64
要达到 25% occupancy(512 thread/SM):
regs/thread ≤ 65536 / 512 = 128
寄存器硬上限:
regs/thread ≤ 255 (超过会 spill)5.9.2 寄存器溢出的代价
CUDA 把 spilled 变量放到 local memory——名字误导,它其实是 DRAM 的一段,但走 L1/L2 cache。延迟梯度(A100 实测):
| 存储 | 延迟 |
|---|---|
| Register | 1 cycle |
| L1 hit (含 spill cache hit) | ~30 cycle |
| L2 hit (spill cache miss → L2 命中) | ~200 cycle |
| HBM (L2 miss) | ~400 cycle |
如果 spill 数据流量大、L1 装不下,频繁 miss 到 L2 甚至 HBM,单次访问慢 200~400×。即使 L1 命中,30 cycle vs 1 cycle 也是 30× 退化。
5.9.3 怎么查实际寄存器使用
方法 1:Triton 的 metadata(最方便)
compiled = my_kernel.warmup(
*args,
BLOCK_SIZE=1024, num_warps=4, num_stages=3,
grid=(1,),
)
compiled._init_handles()
print(f"shared mem : {compiled.metadata.shared} bytes")
print(f"regs/thread : {compiled.n_regs}")
print(f"spilled : {compiled.n_spills} bytes") # 关键!n_spills > 0 就是有 spill。任何值非零都是性能警报。
方法 2:cuobjdump 看 SASS
cuobjdump --dump-resource-usage <kernel>.cubin输出长这样:
Function : add_kernel
Resource Usage:
Common:
GLOBAL:0 CONSTANT[0]:404
REG:42 ← 每 thread 42 个 32-bit 寄存器
STACK:0
SHARED:0
LOCAL:0 ← spill 量,0 = 没 spill
TEXTURE:0
SURFACE:0
SAMPLER:0LOCAL: 字段是真正的 spill 量(字节)。
方法 3:Nsight Compute
ncu --metrics launch__registers_per_thread,\
l1tex__t_bytes_pipe_lsu_mem_local_op_ld.sum,\
l1tex__t_bytes_pipe_lsu_mem_local_op_st.sum \
-k my_kernel python run.py后两个指标是 local memory load/store 字节数——任何不为 0 都是 spill。
5.9.4 减少寄存器压力的五招
按"先试越靠前越好"排序:
1. 减小 BLOCK_SIZE / BLOCK_M / BLOCK_N / BLOCK_K
寄存器占用与 tile 大小成正比。这是首选——简单粗暴,立刻见效。
2. 减小 num_stages
每多一级 stage,编译器要在循环里维护更多临时变量(指针、phase 标志、buffer 选择),单 thread 寄存器涨 5~10 个。
3. 减小 num_warps
降低并行度反而能让单 thread "看着"更多元素,编译器可能把寄存器换成 SRAM 来存——但这是赌博,不一定有效。
4. 手动释放:及早 tl.store,让累加器寿命变短
# 不好:accumulator 一直活到循环结束
for k in range(K):
accumulator += a * b
tl.store(out, accumulator)
# 好:分块写回,编译器能复用 accumulator 寄存器
for block in range(NUM_BLOCKS):
accumulator = tl.zeros(...)
for k in range(K_PER_BLOCK):
accumulator += a * b
tl.store(out + block*..., accumulator)5. 让 tensor 走 shared memory 而不是 register
某些计算可以用 tl.dot 触发 shared-memory layout(自动 stash),把数据从寄存器赶到 SRAM。代价是 SRAM 占用增加。
5.9.5 一个真实案例
OpenAI 在 Blackwell 演讲里展示的 persistent matmul:
配置 1: BLOCK=(128, 256), num_stages=4
→ SRAM = 262 KB > 232 KB H100 限制 → 编译失败 OOM
配置 2: BLOCK=(128, 256), num_stages=3
→ SRAM = 196 KB OK,regs/thread = 168 → occupancy 25%
→ 实测 720 TFLOPS(峰值 989 的 73%)
配置 3: BLOCK=(128, 128), num_stages=4
→ SRAM = 128 KB OK,regs/thread = 96 → occupancy 50%
→ 实测 805 TFLOPS(峰值的 81%) ← 最佳结论:在 H100 上把 BLOCK_N 从 256 砍到 128,虽然单 tile 干的活变少,但寄存器降下来 occupancy 翻倍,总吞吐反而涨 12%。这就是 "occupancy 是手段、不是目标"——但寄存器压力管理对手段的影响必须心中有数。
本章小结
- GPU 是内存系统先行:90% 的算子优化空间在数据搬运,不在算力。存储层次从快到慢依次是 Registers → SRAM (共享内存) → L2 → HBM,速度差 6~10 倍。
- Triton 自动管理共享内存:你不需要写
__shared__,但需要控制BLOCK_SIZE/num_stages/num_warps间接管理预算;目标是单核函数 SRAM ≤ 64 KB。 - 小心寄存器溢出:寄存器溢出到 local memory 实际是 DRAM,会静默拖慢核函数,用
ncu检测。 - L2 优化靠访问顺序:grouped 程序实例排序是一个零算法改动、+10% 性能的经典技巧。
- 矩阵乘法是综合实战:grouped ordering + fp32 累加器 + 软件流水线 + stride 参数化,每个细节都在为内存效率服务。
下一章我们把"挑参数"这件事彻底自动化——@triton.autotune 让编译器替你扫描候选配置,把 BLOCK_SIZE / num_warps / num_stages 的选择从手工活变成搜索题。
思考题
假设你在 A100 上跑一个
BLOCK_SIZE_M=256, BLOCK_SIZE_N=256, BLOCK_SIZE_K=64的 fp16 matmul,开num_stages=3。请估算每个 SM 上的 SRAM 占用,并说明这个配置在 A100(192 KB SRAM/SM)上是否可行。如果不行,你会调整哪个参数?如果把
GROUP_SIZE_M设成1,grouped ordering 会退化成什么?设成num_pid_m(即整个 M 维)又会有什么后果?为什么默认值是8?你在 Nsight Compute 里看到某个 Triton 核函数的 "Spill Stores" 不为零,"Achieved Occupancy" 只有 25%。请提出至少两种可能的修改方向,并说明它们各自的权衡。